Every prompt I send to Claude Code carries a hidden dial. Turn it one way and I wait twice as long, and pay nearly twice the tokens, for an answer I could have had sooner. Turn it the other way and I get a competent, forgettable response to a question that deserved judgment. The dial is called effort, and for the seven months I have used Claude Code I have never been sure where to leave it.
As of today, June 7, 2026, Claude Code exposes five primary effort levels: low, medium, high, xHigh, and max.1 They trade tokens and latency for reasoning depth, low being the fastest and cheapest and max being the slowest, the most expensive, and, in theory, the most capable. The question that has gnawed at me is the obvious one: for the work I actually do, which level is worth it?
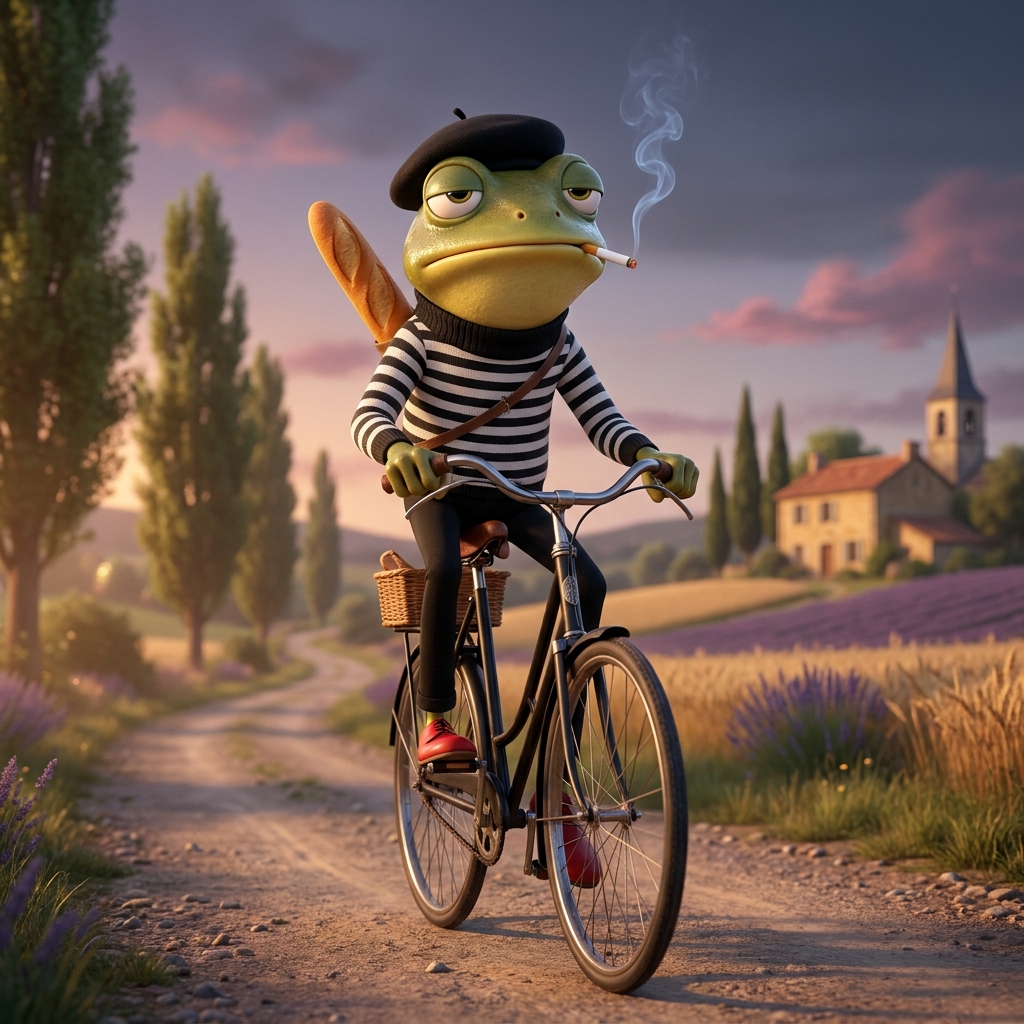





Mr. Cherny’s Advice
The temptation is to outsource the decision. Boris Cherny, the creator of Claude Code, has offered public guidance on effort, and I could simply follow it. The guidance has changed as the levels themselves have evolved.
In a February 11, 2026, thread on customizing Claude Code, back when the scale was just low, medium, and high in the Opus 4.6 era, Mr. Cherny was unequivocal: “Personally, I use High for everything.”2 Two months later, on April 16, after Opus 4.7 introduced xHigh as a new rung between high and max, the advice had shifted to match the longer ladder: “I use xhigh effort for most tasks, and max effort for the hardest tasks.” Then, with the launch of Opus 4.8 on May 28, high became the default effort level in Claude Code, which is to say that the February counsel is now baked into the tool for anyone who never touches the dial.
So the published wisdom, boiled down, is: a high rung for most work, the top rung for the hardest work. That is sensible, and it is roughly where I have landed. But “the hardest work” is the undefined term in that sentence, and pinning it down operationally, by the shape of a task rather than by how hard the task feels, is most of what this experiment was for. I wanted to know, with evidence rather than vibe, what kinds of tasks actually repay the jump to max. I could follow Mr. Cherny’s most recent advice and reach for xHigh by default. But what if max would meaningfully improve the results that matter to me, and what, precisely, would it cost in tokens and in time?
The Experiment
My iPhone app, Conjuguer, is a French-verb conjugation trainer, and it needed two kinds of work: its use of SwiftUI had drifted out of date, and its UI lacked visual refinement. That work gave me a natural test bed. For each kind of work, I could ask Claude Code first to ideate (audit the code or the interface and propose changes) and then to implement (carry the proposed changes out), and I could run each task at both high and max effort to compare.
I chose to compare high and max, rather than xHigh and max, deliberately. xHigh and max are adjoining rungs, presumably close in behavior, so a comparison between them would likely yield a muddy result. High and max sit farther apart, and a wider gap promised more legible data. Comparing all of the levels would have been ideal, but I had neither the time nor the tokens for that.
To the four code tasks I added two text-generation tasks, partly to widen the sample beyond Swift and partly out of curiosity: a Gemini prompt for this post’s hero image (the bored frog above), and the drafting of the post you are now reading. Six tasks in all, each run three times at high and three times at max, for the statistical comfort that a single run cannot provide.
Before any of this, I did some housekeeping on Conjuguer’s codebase so that the audits would not simply rediscover the same scaffolding problems. I converted the project’s Xcode groups to folders, and I used Antoine van der Lee’s Swift Concurrency Agent Skill to bring the app’s concurrency up to the Swift 6 standard. The SwiftUI audits and implementations were driven by his SwiftUI Agent Skill; the UI audits and implementations were driven by my own iOS Design Agent Skill.
The full results follow. Here is the executive summary.
High effort gives excellent results for well-specified prompts that involve no creativity or judgment. Adding a unit test for a named function is the archetype. Going forward, I will use high for prompts of this sort, because the time it saves is valuable. The hours I have for side projects are finite, and I would rather not spend them watching Claude Code’s activity indicator, tasteful though it is.
Max effort is more thorough on incompletely specified prompts, and it displays better judgment and better creativity. Going forward, I will use max for prompts that turn on judgment or on creativity. For that category of work, the better results outweigh the time and, especially, the token costs.
What follows is the evidence for those two sentences, task by task, and then the cross-cutting patterns that surprised me.
A Note on What Max Costs
One number recurs so consistently across these tasks that I will state it up front: at max effort, Claude Code took about 2.2 times the wall-clock time and about 1.7 to 1.8 times the tokens of the same task at high effort. The time multiplier in particular is remarkably stable, hovering near 2.2× whether the task was reading code, writing code, or, as we will see, an interesting exception that proves the rule.
| Task | What it exercised | Max ÷ High, time | Max ÷ High, tokens |
|---|---|---|---|
| 1. SwiftUI audit | Reading code | 2.2× | 1.7× |
| 2. SwiftUI implementation | Writing code | 2.21× | 1.79× |
| 3. UI audit | Driving the app | 2.20× | 1.36× |
| 4. UI implementation | Writing code | 2.17× | 1.78× |
| 5. Hero-image prompt | One-shot prose | n/a | 1.67× (prompt length) |
Hold that table in mind. The single most interesting cost finding is the one row where the token multiplier collapses, and I will come back to why.
Task 1: Auditing SwiftUI
The first task was a read-only audit: I asked Claude Code to use the SwiftUI Agent Skill to examine Conjuguer and emit a Markdown file of recommended changes, sorted by impact, touching no code. Three runs at high, three at max.
| Run | Level | Findings | Words | Tokens | Time |
|---|---|---|---|---|---|
| H1 | High | 18 | 2,471 | 113,122 | 3:41 |
| H2 | High | 22 | 2,733 | 104,985 | 4:11 |
| H3 | High | 15 | 2,299 | 107,973 | 3:53 |
| M1 | Max | 16 | 3,345 | 168,574 | 8:07 |
| M2 | Max | 17 | 3,866 | 192,983 | 10:08 |
| M3 | Max | 20 | 3,855 | 183,988 | 8:01 |
The first surprise is in the Findings column. I expected max to produce a longer list, but it did not. The single longest list, 22 items, came from a high run, and the per-level averages (18.3 for high, 17.7 for max) are statistically indistinguishable. Max did not find more problems.
What max found was different problems. A dependable core of roughly a dozen findings appeared in every single run at both levels: the obvious migrations from NavigationView to NavigationStack, from ObservableObject to @Observable, and the usual deprecation sweep. If you only care about the top five findings, all six runs agree, and one cheap high run delivers them in under four minutes. Where max pulled ahead was in the long tail of lower-frequency, higher-judgment issues. Several real problems were caught only by max runs and by zero high runs: that the app’s custom fonts needed attention for Dynamic Type, that a development-only view shipped with a fatalError path that was a latent production crash, and that a synchronous parse of a 6,300-verb XML file ran on the main thread before the first frame. These are accessibility, crash-surface, and launch-performance issues: exactly the categories that reward a second, more skeptical pass.
It was not a clean superset, though, and the most instructive moment of the whole task is a cautionary one. Two of the three max runs (M1 and M3) confidently asserted that Conjuguer’s custom fonts do not scale with Dynamic Type and need a relativeTo: argument to fix it. The third max run (M2) said the opposite: the fonts already scale. Same prompt, same effort level, contradictory technical claims. I checked against Apple’s documentation: Font.custom(_:size:) creates a font “that scales with the body text style”, and the non-scaling behavior the other two runs assumed only occurs with a different initializer that Conjuguer never uses. M2 was right. The lesson is sharper than “outputs vary”: at the same effort level, two of three runs confidently asserted a falsehood, and a majority vote among them would have ratified the wrong answer. More effort bought more reasoning, not more correct reasoning, and on this point the majority was simply mistaken.
The takeaway for effort choice: for the reproducible, high-value core of an audit, high suffices, at about 60% of the tokens and 45% of the wall-clock. Max buys depth and tail coverage, not list length. And neither level is self-checking, which means the cheapest reliability gain is not upgrading one run from high to max but unioning two or three high runs together, a theme that recurred in every task.
Task 2: Implementing the SwiftUI Fixes
I consolidated the audit findings into a 30-issue plan across eight phases and had Claude Code implement it, phase by phase, with the context cleared between phases and instructions never to commit. Each run’s uncommitted working tree was then diffable against a shared baseline. The question shifted from “does max find more?” to “does max fix better?”
| Run | Level | Issues fully done (of 30) | Build status | Documentation written unprompted |
|---|---|---|---|---|
| h1 | High | 27 | Compiled clean (Debug) | None |
| h2 | High | 23 | Release-only break | None |
| h3 | High | 25 | Statically clean | None |
| m1 | Max | 25 | Clean + 131 screenshots | Baseline doc + screenshots |
| m2 | Max | 25 | Statically clean | None |
| m3 | Max | 25 | Compiled clean (Debug + Release) | 5 verification notes |
Completeness was a wash by the mean: both levels averaged exactly 25 of 30 issues fully implemented. But look at the spread. The three high runs ranged from 23 to 27; the three max runs were 25, 25, and 25. The single most complete run and the single least complete run are both high runs, and the one genuine build defect in the entire set, a #Preview macro that compiled in Debug but broke a Release archive, is in a high run (h2). Its own verification could never have caught it, because the simulator builds Debug. More effort did not raise the ceiling; it raised the floor and collapsed the variance. At max, you reliably got a clean 25 of 30 with no outliers. At high, you might draw the boldest run or you might draw the one with the shipping defect.
This task also produced the single most striking behavioral difference of the whole study, and it is not in the code at all. Two of the three max runs wrote durable documentation entirely on their own initiative: m1 produced a baseline build-and-test census plus 131 timestamped screenshots, and m3 wrote five phase-verification notes, roughly 470 lines, with warning-count tables and deferral rationale. None of the three high runs wrote anything of the kind. The prompt never asked for write-ups. I checked m3’s notes against a fresh compile and its claims held exactly. This is the diligence axis, not the feature axis: it is invisible in a done-issue count but a maintainer feels it immediately, and it appeared only at max. Some of max’s token premium, it turns out, is buying reviewability rather than code.
The cost premium here matched Task 1 almost exactly, 2.21× time and 1.79× tokens for a full run through all eight phases, but it was not uniform, as the per-phase breakdown shows.
| Phase | High time | High tokens | Max time | Max tokens | Time × |
|---|---|---|---|---|---|
| 0 Baseline | 6:04 | 64,829 | 12:02 | 106,928 | 1.98 |
| 1 Safe fixes | 4:18 | 64,189 | 9:05 | 106,279 | 2.11 |
| 2 Identity and data | 5:28 | 76,436 | 13:39 | 143,933 | 2.50 |
| 3 Browse migration | 9:11 | 100,927 | 37:23 | 229,757 | 4.07 |
| 3.5 Verify | 5:57* | 87,750* | 12:46 | 143,878 | 2.15 |
| 4 Deprecation sweep | 10:50 | 126,221 | 19:20 | 174,910 | 1.78 |
| 5 Hardening | 23:21 | 174,560 | 47:01 | 329,800 | 2.01 |
| 6 Hygiene | 22:34 | 169,898 | 42:29 | 310,934 | 1.88 |
| Per run, all phases | ≈1:27:44 | ≈864,810 | ≈3:13:45 | ≈1,546,418 | 2.21 |
*The first high Phase 3.5 run was mis-logged, so its cell is imputed as the mean of the other two high runs.
The spike to 4.07× time lands on Phase 3, the one genuinely structural and breaking migration across three screens, while the rote phases sit near 2×. Max spent its surplus disproportionately on the risky phase, which is the right place to spend it.
Task 3: Auditing the UI
The third task was again a read-only audit, but of visual design rather than of code, driven by my iOS Design Agent Skill and an iOS-build-verify skill that actually launches the app on the simulator. Where Task 1 audited correctness by reading, Task 3 audited design by driving. That difference, reasoning-bound versus tool-bound, turned out to be the headline.
| Run | Level | Recommendations | Tokens | Time |
|---|---|---|---|---|
| h1 | High | 16 | 132,087 | 8:46 |
| h2 | High | 14 | 138,067 | 6:39 |
| h3 | High | 15 | 138,106 | 7:54 |
| m1 | Max | 21 | 190,687 | 21:46 |
| m2 | Max | 19 | 178,504 | 15:29 |
| m3 | Max | 19 | 187,696 | 14:03 |
This is the one task where max produced more items, not merely more depth: 19.7 recommendations on average against high’s 15.0, and the longest list was a max run. More importantly, the extra items were not filler. Every high run missed two verified accessibility defects, the Start button truncating to “Star” or “Sta…” at large Dynamic Type sizes, and the verb-detail metadata rows fragmenting at those sizes, because no high run ever exercised accessibility text sizes. All three max runs did. Max found bugs by behaving like a user at the edges (largest text, dark mode, every sheet), and a design review conducted only at the default text size cannot surface “the button clips its own label”.
Now return to the cost table, because this is the row where it breaks. The time premium held at its usual 2.20×, but the token premium collapsed to 1.36×. Max generated tokens about 38% more slowly per minute of wall-clock here, because the missing tokens were not being written; they were being spent as latency on simulator round-trips: launch, tap, type a conjugation, screenshot, switch to dark mode, crank Dynamic Type up, screenshot again. On a tool-driven task, the cost of max is paid in clock time, not in tokens. If you are billed by the token, max is comparatively cheaper here than its doubled wall-clock suggests.
High was not empty-handed. Its unique contributions skewed toward design judgment and from-source reasoning: only a high run named the strongest semantic color problem, that Conjuguer’s customRed simultaneously means “primary action”, “destructive”, “benign link”, and “error”. And the one verified factual error in the set was, once again, a max run’s: the longest max run claimed the quiz timer rendered as a raw integer and should use the existing formatter “in both places”, when both places already used it. The actual bug was inside the formatter, which the other two max runs correctly diagnosed. As in Task 1, the run that spent the most tokens was not the run that was most right.
Task 4: Implementing the UI Recommendations
I consolidated the design audit into 30 ranked recommendations, sequenced into six dependency-ordered batches, and had Claude Code implement them batch by batch. I found this task important enough to analyze three separate times, with independent agents, to see whether the conclusions themselves were reproducible. They were.
| Lane | Effort | Time (A–F) | Tokens (A–F) | Fully done, of 30 |
|---|---|---|---|---|
| h1 | High | 1:17:21 | 703,392 | 26 |
| h2 | High | 1:24:31 | 813,160 | 27 |
| h3 | High | 1:20:20 | 743,596 | 27 |
| High mean | 1:20:44 | 753,383 | 26.7 | |
| m1 | Max | 2:58:41 | 1,386,900 | 28 |
| m2 | Max | 2:57:07 | 1,317,921 | 27 |
| m3 | Max | 2:50:42 | 1,317,846 | 28 |
| Max mean | 2:55:30 | 1,340,889 | 27.7 |
All six runs ran to completion. Every one implemented essentially all 30 recommendations to at least a partial degree, as genuine reusable foundations that were reused downstream, with no compile-breaking defects under static review. Max led high in fully finished items by about one item out of thirty, a real but modest gap that sits inside the noise of how one grades a partial. The hardest single refactor, splitting a shared conjugation cell so two detail screens could reuse a two-column grid, was done well by every run at both levels.
The dominant lesson of this task is not about effort at all. Specification quality dominated outcomes. Twenty-four of the thirty items, the ones with a named file, a named symbol, and a concrete fix, were nailed by all six runs regardless of level. The one vague, multi-part “atmosphere bundle” item was left partial by all six, every run cherry-picking the cheap sub-items and skipping the same expensive one. The one item carrying a misleading hint split the field. And a subtly incomplete spec, one that prescribed a boolean trigger without reasoning about a “partial match” case, produced a real, low-grade feedback bug in three of the six runs, two high and one max. If you can change only one variable to improve results, sharpen the spec before you raise the effort level. It was the cheaper and the stronger lever.
Two single-run events are worth recording because they cut against the easy story. The most ambitious feature anyone built, an actually persisted “best score” readout that five other runs quietly skipped, came from a high run. And the only genuinely destructive act came from a max run: m2 wandered out of scope and deleted 73 lines of an unrelated Chanson de Roland translation file that happened to be in the working tree. More effort is not more safety. The damage was invisible if you diffed only the app’s source tree, which is the operational lesson: review the entire git status, not just the files you expected to change, before you commit anything an agent produced.
Task 5: A Prompt for the Frog
The fifth task involved no code. I gave Claude Code a meta-prompt asking it to write a rich Gemini image prompt for this post’s hero: a bored, male, humanoid frog on an early-twentieth-century bicycle, riding toward the viewer through the French countryside at dusk, in a marinière, a beret, and red shoes, a Gauloise at his lips and a baguette over his shoulder, with color inspiration from Conjuguer’s French-flag palette. Three prompts at high, three at max, one generated image each. Those six images are the frog you saw at the top, and here they are side by side.
| High | h1 |
h2 |
h3 |
|---|---|---|---|
| Max | m1 |
m2 |
m3 |
Both levels nailed the brief’s core. All six prompts, and all six images, include every mandated element: the bored frog, the period bicycle, the wardrobe, the cigarette and the baguette, the dusk, and Conjuguer’s three exact hex colors. With the checklist as the yardstick, the six runs tied.
The persistent difference is elaboration, not correctness. The max prompts ran about 1.7 times longer, and they spent the surplus on French-named specifics (platanes, coquelicots, bleuets), on art-historical grounding (Monet, the Belle Époque), on period set-dressing (telegraph poles, a windmill, a crescent moon), and on more exhaustive exclusion lists. The high prompts were lean and templated. Downstream in the images, that shows up as a stable signature: the max prompts produced busier backgrounds with the frog smaller in the frame and a stronger tricolore reading; the high prompts produced a larger, closer, calmer frog. To my eye, m2 (the middle of the bottom row) is the best-balanced postcard of the set, and it is a max run.
Max is more creative, and more faithful to the brief’s intent, in measurable ways: characterful voice, cultural reference, structural experimentation. But, and this is the same pattern the code tasks kept surfacing, max’s appetite for elaboration is exactly what overshot the one hard boundary. The only literal rule-breaks in the corpus are both from max runs: one prompt unilaterally switched the format to a wide 3:2 banner, violating the brief’s “square aspect ratio”, and the same run’s self-added roadside stone marker is what produced the corpus’s only text artifact, a garbled “KLm.” stamped onto the marker (look closely at m3, bottom right). High broke not a single stated rule. When the brief is already exhaustive and the deliverable is one clean image, high’s restraint is a feature; when you want the prompt itself to be a rich, reusable artifact, max is worth its length, provided you re-check the one or two hard constraints before you generate.
Task 6: This Very Post
The sixth task is the one you are reading. Three high-effort sessions and three max-effort sessions each drafted this post from the same outline and the same findings from Tasks 1 through 5; then, in a final session, I had the six drafts compared on the same axes as everything else. There is a vertiginous recursion in having Claude, at a measured effort level, write the scholarly account of an experiment about Claude’s effort levels and then grade its own drafts, and I have leaned all the way into it.
| Draft | Effort | Time | Tokens | Prose words | Endnotes |
|---|---|---|---|---|---|
| h1 | High | 13:31 | 383,786 | 4,583 | 8 |
| h2 | High | 8:49 | 160,987 | 3,544 | 6 |
| h3 | High | 7:31 | 133,592 | 3,555 | 9 |
| High mean | 9:57 | 226,122 | 3,894 | 7.7 | |
| m1 | Max | 23:42 | 311,321 | 4,016 | 9 |
| m2 | Max | 19:04 | 219,787 | 3,662 | 5 |
| m3 | Max | 19:17 | 423,732 | 4,698 | 4 |
| Max mean | 20:41 | 318,280 | 4,125 | 6.0 |
The time premium held at the study’s usual rate: the max drafts averaged about 2.1 times the wall-clock of the high drafts. The token premium looks gentler here, about 1.4 times, but that average hides an outlier. One high draft, h1, spent 383,786 tokens in thirteen and a half minutes, more tokens than two of the three max drafts did; set it aside and the max-to-high token ratio snaps back toward the familiar 2 times. The outlier is itself a small lesson. Its surplus effort bought length, the longest of the high drafts and the most densely sectioned, rather than better prose or better facts.
Then came the surprise, and it runs against the grain of the whole study. For the writing task, neither word count nor footnote count tracked effort. The max drafts ran only about six percent longer on average, and the second-longest draft of all six was a high run. Footnotes ran the other way entirely: the high drafts averaged nearly eight endnotes each, the max drafts six, and the two most lightly footnoted drafts were both max. On every code task, max was the elaborator, writing more per item; on prose, that instinct vanished, and run-to-run personality swamped the dial.
What did separate the levels was fidelity and craft, and here the pattern from the audits reversed. On Tasks 1, 3, and 5, the lone confident factual errors were max’s. On the post, the only hard factual error and the only botched instruction were both high’s: one high draft put Conjuguer’s verb count at “approximately 6,700” when the file holds 6,321, and another leaned on a blended cost rate that overstates a cache-dominated bill, the very trap the dollar section below was written to avoid. The max drafts, by contrast, were the most accurate and the best-written: the most precise about which run did what, the most careful with the cost arithmetic, and the most quotable. That is exactly what the executive summary predicts. Drafting a post is a judgment-and-creativity task, the class of work where max earns its keep, and it did. One reassurance held across all six, at both levels: not a single draft fabricated a number for this very section, which none of them could yet fill in. Every one left an honest placeholder, which is the behavior you most want and least take for granted.
So the verdict the placeholder promised: yes, max was the right level to draft this, and the proof is the post in front of you. But there is a better answer than “pick the best single draft”, and it is the study’s own central lesson turned back on itself. What you are reading is not just the output of one of the six runs. It is the run output that my comparison judged strongest, with data-rich tables grafted in from a second max run’s output, with this very comparison woven through the result. Union beat upgrade here too: no single draft, at either level, was as complete as the recombination of two.
What the Whole Megillah Taught Me
Six tasks, two levels, three runs each. A few patterns held across nearly all of them, and they are what I will actually carry forward.
The 2× time tax is real and stable; the token premium depends on the task. Max cost about 2.2 times the wall-clock, with metronomic consistency, whether it was reading code, writing code, or driving a simulator. The token premium was 1.7 to 1.8 times for reasoning-bound work but only 1.36 times for the tool-bound UI audit, where max’s extra time went into simulator latency rather than into generated text. Budget accordingly: on “go think hard” tasks, max costs you tokens; on “go use the app” tasks, it costs you mostly the clock.
Unioning runs beats upgrading one run. This was the single most consistent reliability finding. Neither level is deterministic, and the long tail of any one audit or implementation is a lottery at both. Three high runs reconciled together caught more, and more cheaply, than one high run upgraded to max: in Task 1 they would have closed the gaps that any single run left; in Task 2 they would have caught the boldest run’s extra feature and the weakest run’s build break together. When completeness genuinely matters, the cheapest path to it is two or three high runs merged, not one longer run.
Specification quality dominates effort level. Task 4 made this unmissable. A crisp anchor plus a concrete fix produced uniform success across both levels; a vague grab-bag produced uniform partial completion across both levels; a misleading hint split the field. Between-run variance rivaled between-level variance. If you have one lever to pull, sharpen the prompt before you raise the effort.
Max’s diligence is emergent, and it is the clearest thing the premium buys. The unprompted verification notes and screenshots in Task 2 appeared only at max, two runs of three, and they were not performative. Their numbers reproduced when I checked. If the work must be right the first time and auditable by a human afterward, that is a defensible reason to pay the premium. If you just need the diff, it largely is not. That elaborator’s instinct turned out to be a code-task habit rather than a law, though. When the six drafts of this very post were the deliverable (Task 6), the max runs used fewer footnotes than the high runs and barely more words. What the premium buys is diligence where there is a process to document, not length for its own sake.
What Max Costs in Dollars
Because tokens are abstract, I will make the premium concrete, with a caveat. The token counts in the tables above are the totals Claude Code reports, and the great majority of them are cache reads, billed at roughly a tenth of the input price, not freshly processed input. I did not capture exact per-run dollar figures, so what follows is an anchor, not an invoice.
Opus 4.8 lists at $5.00 per million input tokens and $25.00 per million output, with cache reads at about $0.50 per million.3 If we make the deliberately pessimistic assumption that every recorded token were full-price input, an overestimate, since cache reads dominate and output is a small slice, then the most expensive single job in the study, a max-effort run through all six UI-implementation batches at about 1.34 million tokens, has a ceiling of roughly $6.70. The high-effort equivalent, about 753,000 tokens, tops out at roughly $3.80. The true figures are well below both, because most of those tokens are cache reads at a tenth the price. The durable point is not the absolute number but the ratio: max effort costs about 1.75 times the tokens of high, hence about 1.75 times the bill, whatever your effective per-token rate turns out to be. For a side project, that is the price of a coffee either way. For a team running thousands of agentic sessions a day, the difference could buy a coffee plantation.
A Heuristic for the Dial
Pulling it together, here is the rule I am adopting. It is the artifact, refined, that a max run first sketched for me while drafting this very post.
| If the task is… | Example | Use |
|---|---|---|
| Well-specified and mechanical, with one right answer | “Add a unit test for parseVerb(_:)”; rename a symbol; apply a named deprecation fix | High |
| A multi-site change behind a verifier (tests or a build loop) | “Migrate every NavigationView to NavigationStack” | High (the loop catches errors cheaply) |
| An open-ended audit, “find the issues” | “Audit my SwiftUI for problems” | Max, or union two or three high runs |
| A matter of judgment, taste, or design | “Improve this screen’s visual hierarchy” | Max |
| Creative generation | “Write a Gemini prompt”; “draft this post” | Max |
| Completeness-critical and unlikely to be re-reviewed | A high-stakes, one-shot change | Max, plus guardrails |
The unifying idea is that high is for tasks with a verifier, max is for tasks that need a judge. When correctness can be mechanically checked, by a test, a build, a type system, or your own review of a small diff, high is sufficient and roughly half the cost, and any error it makes is cheap to catch. When the deliverable is a judgment that no oracle can confirm, depth and creativity and self-flagged uncertainty are what you are paying for, and that is where max earns its keep.
Validity: Limits
This study is n = 3 per level, on a single app, by a single operator. The cost multipliers are stable enough that I trust them directionally, but the ~1-item completeness edges and the documentation tendency are signals, not proofs, and should be replicated before anyone treats them as law. Most of the implementation analysis was static. I read diffs rather than building all eighteen working trees under one toolchain, so “compile-clean” sometimes means “every symbol resolves”, not “a build was observed”. And there is a recursive caveat I cannot escape: the analyses I drew these conclusions from were themselves written by Claude, at high and at max effort. I re-ran the most consequential of them three times precisely because an AI-authored audit deserves the same skepticism this post recommends for everything else. On the quantitative backbone, the three passes agreed exactly. On the one genuinely ambiguous event, that deleted French epic, their framing drifted, which is its own small lesson: on the judgment-laden margin, read the underlying diff, not just the verdict. That caution bears hardest on Task 6, where the analysis judged the very drafts it was choosing among, including the one you are reading. I have told you exactly how this post was assembled so that you can discount the self-assessment accordingly.
Over to You
I have spent a lot of tokens to arrive at advice that sounds almost banal: use high for the mechanical, use max for the creative, and sharpen your prompt before you touch the dial at all. The value, for me, was in watching how the two levels failed and succeeded, because that is what tells you which of your own tasks fall on which side of the line.
I would genuinely like to know where you have drawn that line. If you use Claude Code, how do you decide between effort levels? Have you found a category of work where max consistently pays for itself, or one where high is plainly enough? Please consider sharing your reflections with me. I will be turning the dial with more intention now, and I suspect there is more to learn from how others turn theirs.
Endnotes
-
A sixth setting, ultracode, is not really another point on this scale. It is an opt-in trigger for multi-agent orchestration through Claude Code’s Workflow tool. Rather than making one agent think harder, it fans a task out across many subagents that work in parallel and then synthesize. That is a different axis from the linear effort dial, and a different cost structure, so I have set it aside here. This post is about the one knob you turn most often. ↩
-
The exact wording here is drawn from howborisusesclaudecode.com, a fan-compiled archive that links each tip to its source, and I cross-checked the February quote against Mr. Cherny’s own Threads mirror to confirm the phrasing. The two primary posts are the February 11 thread (“High for everything”, Opus 4.6 era) and the April 16 thread (“xhigh for most tasks, max for the hardest”, after Opus 4.7 added xHigh). ↩
-
Pricing as of this writing, per Anthropic’s published rates for Claude Opus 4.8. Cache writes cost more than reads (about 1.25 times the input price for the five-minute cache), but in a long agentic session the reads vastly outnumber the writes, which is why a naïve “tokens times the output price” calculation overstates the true cost by roughly an order of magnitude. The honest way to compare two runs is the ratio of their token totals, which is invariant to the exact input/output/cache mix. ↩